
As organizations continue to embrace containerization and microservices, the need for efficient monitoring solutions has never been more critical. Prometheus, with its robust monitoring capabilities, has become a go-to choose. However, Prometheus scaling challenges arise as systems grow in complexity and scale.
In this article, we will explore these challenges and discuss strategies to overcome them when scaling Prometheus in large systems.
Understanding Prometheus Scaling Challenges
Prometheus is renowned for its simplicity and effectiveness in collecting and querying metrics. However, as systems grow larger and more complex, several challenges can hinder its performance and scalability:
- Increased Data Volume
In large systems, the volume of metrics generated can be overwhelming for a single Prometheus server. Handling millions of time-series data points per second can lead to increased resource consumption and reduced query performance.
- High Cardinality
High cardinality, which occurs when there are many unique labels associated with metrics, can strain Prometheus. It can lead to memory usage spikes, making it challenging to maintain efficient storage and querying.
- Resource Constraints
Prometheus servers are not immune to resource limitations. Memory, CPU, and storage constraints can impact their ability to handle a growing number of targets and metrics efficiently.
- Single Point of Failure
Running a single Prometheus server poses a risk of a single point of failure. If that server becomes unavailable, monitoring and alerting for the entire system can be disrupted.
Strategies to Overcome Prometheus Scaling Challenges
To address these challenges and scale Prometheus effectively in large systems, consider the following strategies:
- Horizontal Scaling
Horizontal scaling involves deploying multiple Prometheus servers and distributing the workload among them. This approach not only enhances fault tolerance but also allows for better resource utilization.
Benefits of Horizontal Scaling:
- Enhanced Performance: Multiple Prometheus instances can handle higher data ingestion rates.
- Improved Fault Tolerance: If one instance fails, others can continue to operate.
- Scalability: Easily add new Prometheus instances as your system grows.
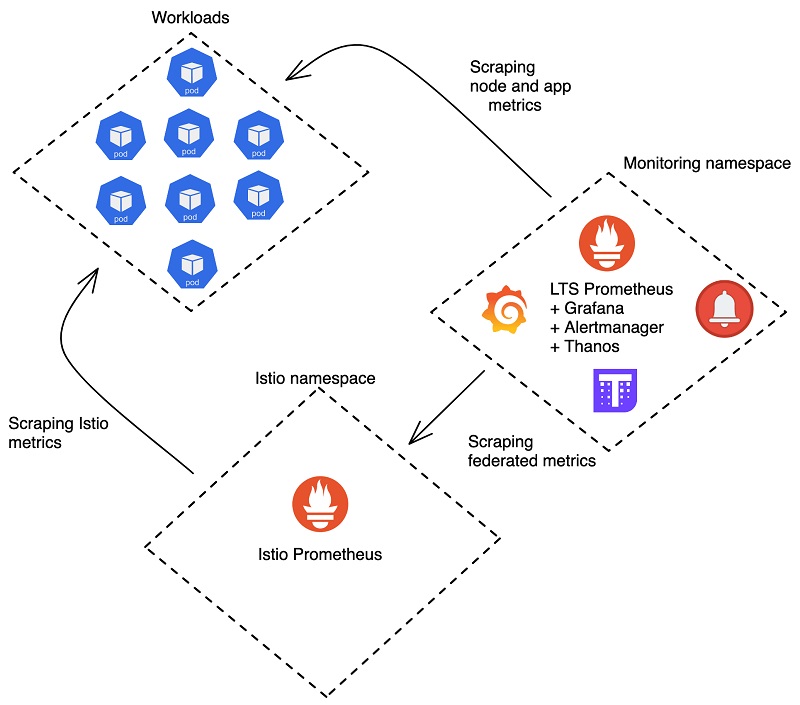
- Federation
Prometheus Federation enables you to scrape metrics from one Prometheus server into another. This is particularly useful when dealing with geographically distributed systems or when you have multiple Prometheus instances across various environments.
Benefits of Federation:
- Centralized Monitoring: Aggregate metrics from different Prometheus instances for a unified view.
- Load Distribution: Reduce the number of targets each Prometheus instance scrapes directly.
- Geographical Distribution: Collect metrics from remote sites or regions.
- Thanos and Cortex
Thanos and Cortex are projects designed to extend Prometheus with features like long-term storage and high availability. Thanos, for instance, integrates with object storage systems like Amazon S3 or Google Cloud Storage, allowing you to store metrics data for extended periods.
Benefits of Thanos and Cortex:
- Long-term Storage: Retain metrics data for extended periods without worrying about storage limitations.
- High Availability: Ensure uninterrupted monitoring with distributed setups.
- Scalability: Handle increasing workloads and storage requirements effectively.
- Load Balancing
Implementing a load balancer in front of multiple Prometheus servers can evenly distribute incoming requests and scrape targets, ensuring each Prometheus instance operates efficiently.
Benefits of Load Balancing:
- Improved Performance: Distribute traffic evenly, preventing bottlenecks.
- High Availability: Minimize downtime by redirecting traffic in case of server failures.
- Scalability: Easily add or remove Prometheus instances without disrupting monitoring.
Conclusion
Prometheus is a powerful monitoring tool, but it’s crucial to address Prometheus scaling challenges effectively as your systems grow. Monitoring is a critical aspect of maintaining system health and ensuring optimal performance, making these scaling strategies essential for modern IT operations.